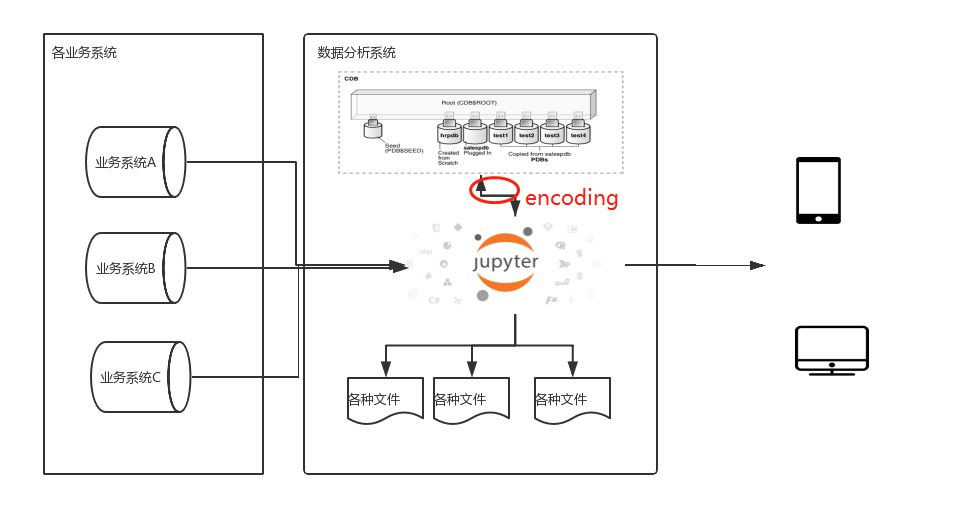
1. 系统结构及问题
最近在搭建基于Jupyter notebook,panda,dash plotly的数据分析系统。从各个业务系统抽取数据,分析展示。
难免会涉及到中间数据保存,最后返现还是绕不开数据库。为了方便选了Oracle XE,看重其pluggable PDB实在是方便,每个库还可以不同字符编码,兼容各个业务系统。
然鹅,当我用pd.to_sql输出到DB的时候,却发现各种编码问题,并不是SQLAlchemy create engine的时候指定编码就能解决的。
2. 数据读取
当业务系统库是UTF-8,我在XE DB中建了一个UTF-8的PDB,本已实现免除encoding转换。各库中都保留原来的编码,python中提取之后都是unicode,理想很完美。
现实是当我用cx_Oracle读取UTF-8业务库的数据,pandas中数据内容很正常。
此处穿件连接的encoding选项功能很正常。
1 | con = cx_Oracle.connect(data_driver.MAIN_CONNECT_STRING,encoding="UTF-8") |
3. 数据写入PDB
写入数据库时,如果直接用cx_Oracle驱动代码比较麻烦,一般直觉肯会用Pandas的DataFrame.to_sql。这样底层的令人痛疼的create table, insert 都一边去,自己要做的就是在pandas里面整理数据,to_sql扔给数据库持久化保存。从效率来看,to_sql也远比 to_excel效率高,节省资源。
写入数据库,代码节大概如下。
1 | #SQLAlchemy 建立数据库engine |
写代码的时候自信满满以为照顾到了各方编码,结果还是出来GBK编码错误. 数据中心有'\xa0'全角空格,gbk无法编码。
返回错误
1 | UnicodeEncodeError: 'gbk' codec can't encode character '\xa0' in position 0: illegal multibyte sequence |
4. 问题排查及解决
错误出来之后,首先想到的是数据库编码有问题。
重复检查数据库,确实双方都是UTF-8, 分析用的XE PDB中也确实是UTF-8, 手工录入'\xa0'都没有问题。所以排除数据库自身编码的问题。
其次想到的是操作系统默认编码,因为服务器是windows,通过chcp 650001,改变默认编码为unicode,在启动python,这样貌似没地方会使gbk编码了吧。应该完美了。
测试之后,还是被打脸了,错误信息一点变化都没有。
最后想排查cx_Oracle 和SQLAlchemy 这两个库。
读取数据的时候pandas直接使用的cx_Oracle 连接,指定utf-8编码之后数据是正常的,所以基本上定位是SQLAlchemy的问题。
创建engine的时候,这里指定的encoding是否有效存疑啊。看来还是SQLAlchemy和cx_Oracle集成的时候出现了问题。
1 | engine = create_engine('oracle://' + 'DATANA:datana@XE_PDB3',encoding='utf-8') |
翻了几篇官方文档,试了各种。。。。此处省略一万种选择。最后找到希望
Custom DBAPI connect() arguments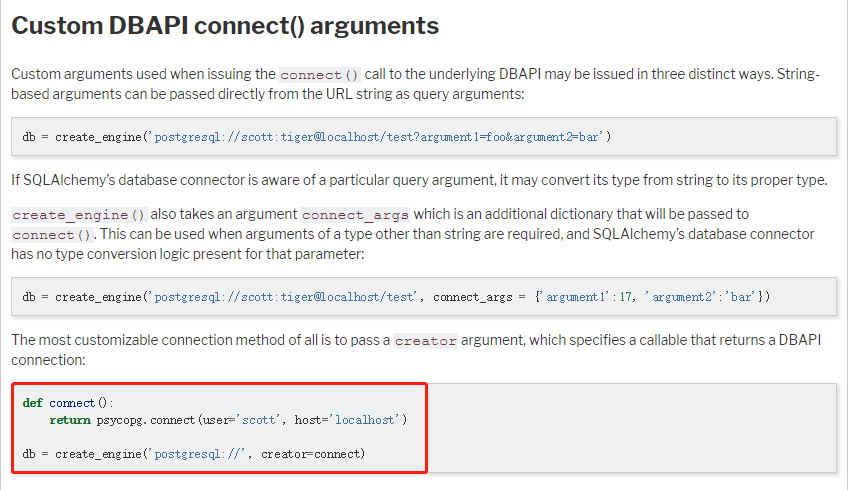
SQLAlchemy对于创建 engine这件事情,提供了深度客制化的选择。对于cx_Oracle兼容不太满意的情况,可以自己建一个creator,保证cx_Oracle的配置都做好之后,再传给SQLAlchemy。
代码示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# 定义基于cx_Oracle的creator,在里面生成connection,保证使用UTF-8编码。这是能正常work的,在读取的时候也验证过。
def con_creator():
return cx_Oracle.connect('datana/datana@XE_PDB3', encoding="UTF-8")
#连接库生成SQLAlchemy engine时,调用creator,这时encoding写上就写上吧,可能真没用。
engine = create_engine('oracle+cx_oracle://', creator=con_creator ,encoding='utf-8')
#写数据,这回没有烦人的encoding 错误了。拜拜了gbk
df_all.to_sql(name='表明_table'
,con=engine # utf-8 的sqlalchemy engine
,if_exists='replace'
,chunksize=10000
,dtype={ 'column name' : sqlalchemy.types.VARCHAR(10) # 对于pandas中object的列,要定义类型,否则。。。自动clob也是慢
}
,index=False
)
摆脱了这个编码问题,继续我建设功能感人的数据分析平台之路。